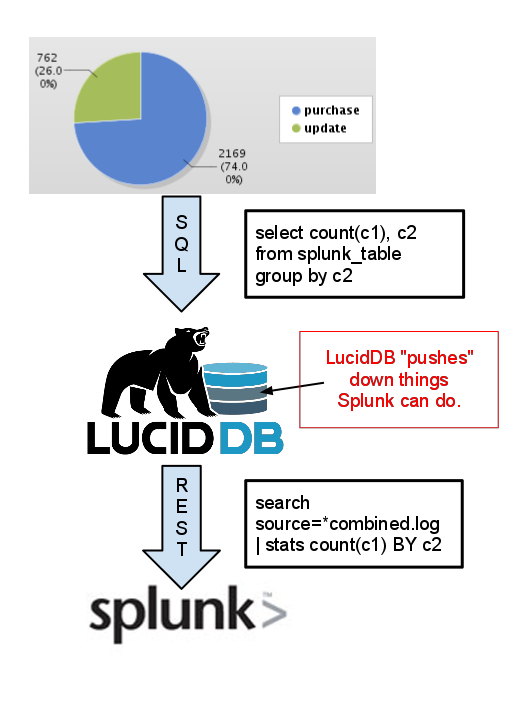
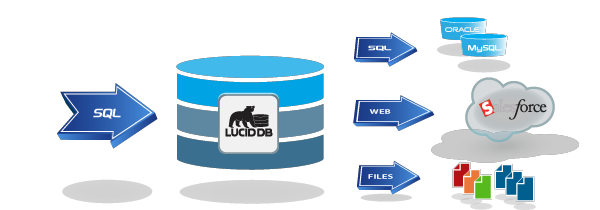
Following up on my first post on an alternative, more SQL-eee metadata driven approach to doing BI on Big Data, I’d like to share an example on how we can enable easy reporting on top of BIg Data immediately for CouchDB users. We’re very keen on discussing with CouchDB/Hive/other Big Data users about their Ad Hoc and BI needs; please visit the forum thread about the connector.
We’ve been working with some new potential customers on how to leverage their investment in Big Data (specifically Big Couch provided by the fine folks at Cloudant. In particular, this prospects users are thrilled with their dashboards and analytics that are baked into their application, but they need to be able to enable Ad Hoc, easy analysis on top of their data via a traditional reporting tool. Like any organization, IT is overworked and reports always seem to find their way to close to the back of the priority. Our initiative at this customer is about enabling easy access to their high performance and well tuned/architected CouchDB instance.
I figured I could generalize what we’re doing at this prospect to a more general post, and hope that this post (and the software behind it, namely LucidDB) finds there way into the hands of others that are trying to do Ad Hoc and easy SQL based analytics on top of CouchDB.
First, the overview:
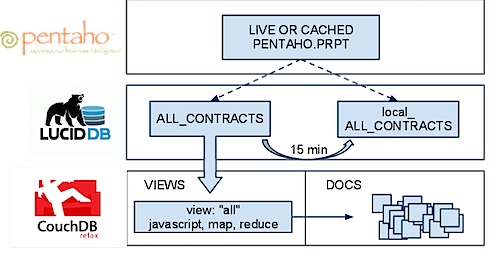
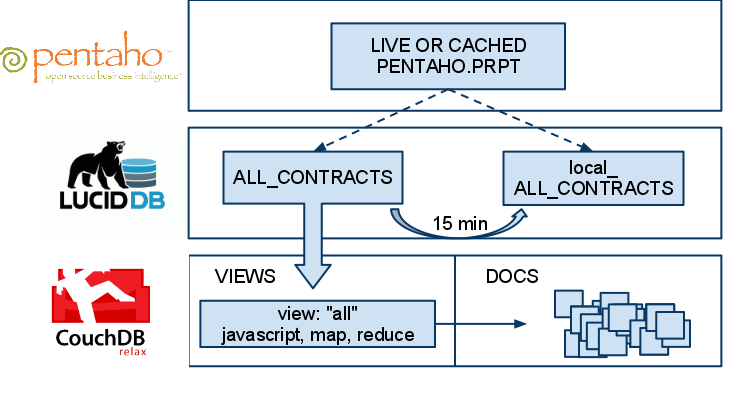
We’ve created a solution that allows HTTP views in CouchDB to be made accessible via SQL inside of LucidDB. This means two things:
- Direct access to LIVE, real time data in CouchDB is available to any tool that can talk to LucidDB (SQL + JDBC/ODBC).
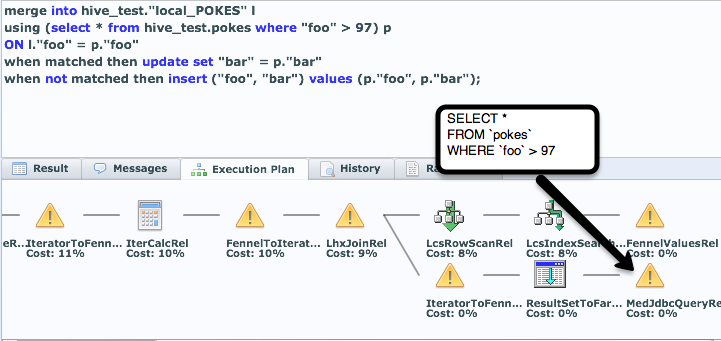
- We can use this access to very easily, keep a cached up to date “cache” of this data in LucidDB, an optimized column storage database. In fact, the periodic refresh is a single MERGE statement (TO BE COVERED IN A SUBSEQUENT BLOG)
Our vision of Big Data BI requires that the user be able to “choose” which version of the data they want, easily. Cached and summarized inside LucidDB -OR- up to date, real time results from Big Data (aka CouchDB). This example focuses on the first part of the “hot or cold” level of aggregation ability; namely the live “HOT” piece.
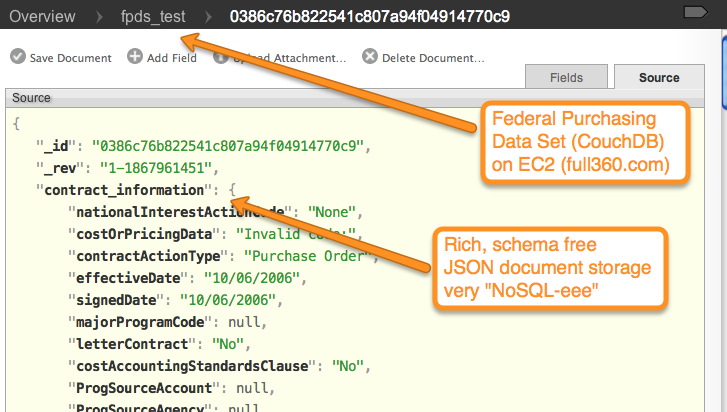
First, let’s look at our source data. We’ve used the Federal Purchasing Dataset (a sample of 1000 records, since this runs on my laptop). Here’s a couple of screenshots from Futon that show the source data docs, and then the CouchDB View.
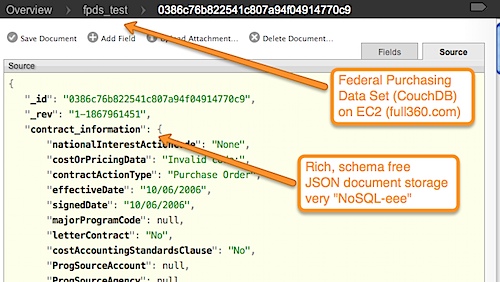
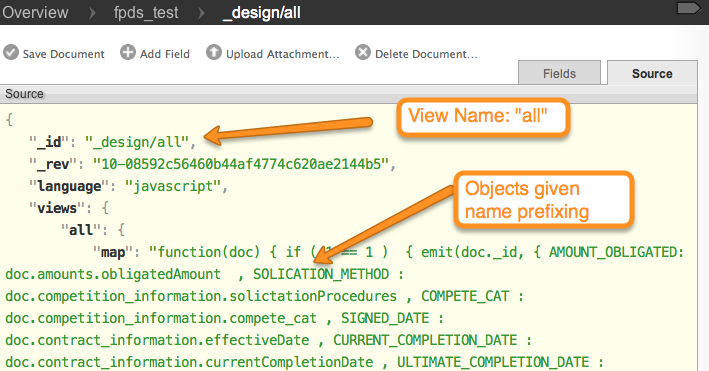
and also the “view” that we’ll access
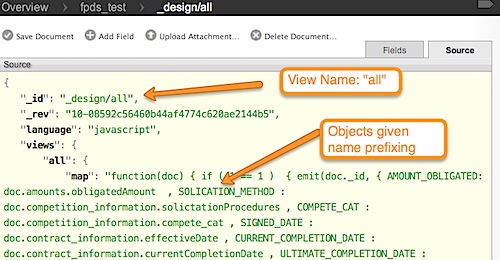
NOTE: This view is definitely atypical. It is just emitting docs/flattening. it is NOT doing any aggregation with is what is almost always done with HTTP views. Our connector initially supports streaming data from the values, but we’re already working on getting proper support for the KEYs (and ability to push down group_level, etc).
There’s another key piece of our philosophy on Big Data BI that is also present here. Notice that we’re not trying to “dumb down” the source, Big Data system? We’re not trying to strangely Map SQL onto some remote language so that you’ve lost some richness. CouchDB’ers take note: You can do all that you normally can and want to do in that view. We believe in effeciently accessing (group_level optimizations) not about reducing your abilities to write very interesting, complex map / reduce that returns your base level results.
Let’s make these available, via ANSI SQL, in LucidDB.
I’ll start with a vanilla installation of LucidDB (NOTE: I used a pre release version of 0.9.4 for this).
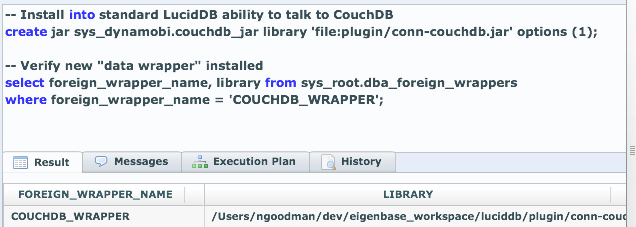
First, let’s give LucidDB the ability, in a general way, to talk to CouchDB as a foreign data source:
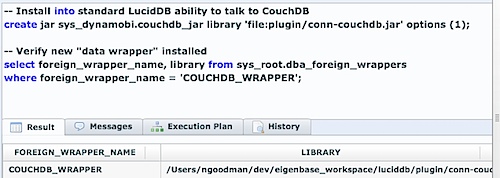
Now LucidDB has the ability to talk to CouchDB, in a general sense. Let’s now configure and access our test dataset.
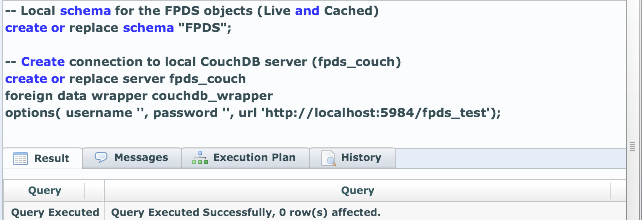
First step is to create a server connection from LucidDB to our CouchDB server:
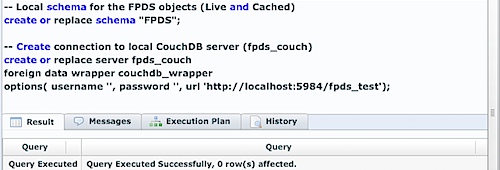
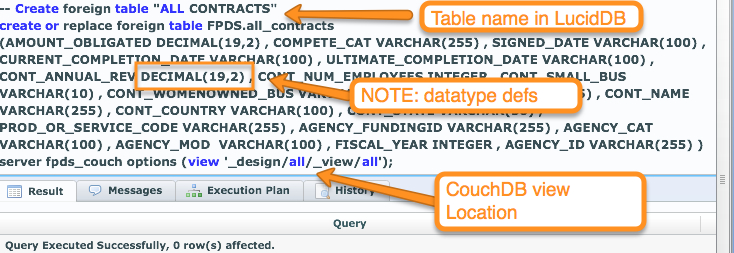
Now, we’ve established a connection from our LucidDB installation to CouchDB; let’s now make that “all” view available via SQL.
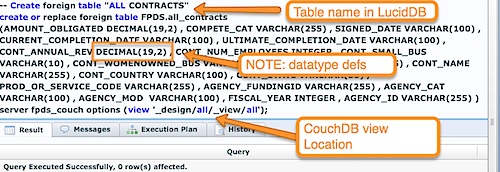
That statement looks complicated. It is, unfortunately, a little more involved than this process usually is. If you were talking to say, Oracle database, we can import and “discover” all this information (datatypes, column names, etc) from the driver. We have not done all this additional metadata work for the CouchDB connector yet; or actually, how to get ALL this information from the remote view as well.
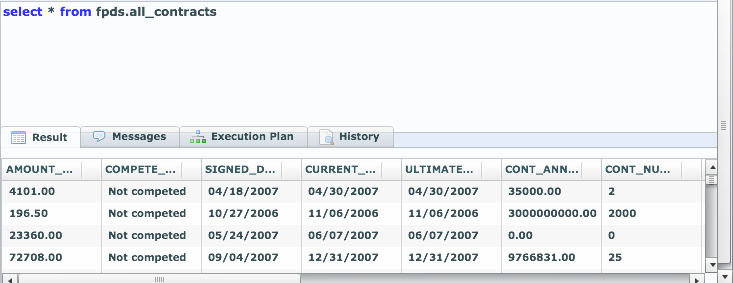
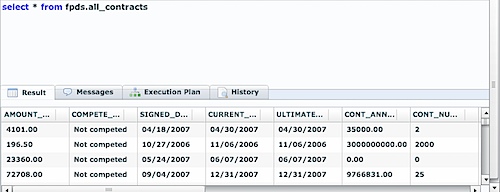
So, we’ve told LucidDB about the server, the view, the datatypes/fields. We’re all set to now do ANY SQL we like on top of it.
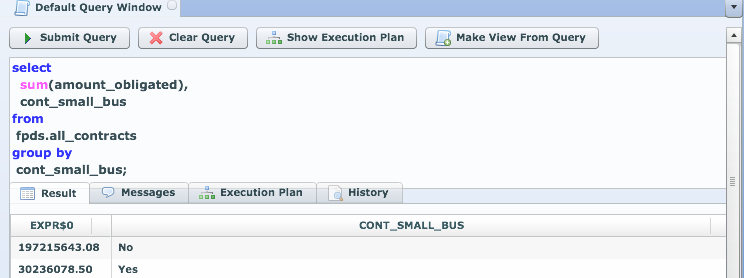
How about doing some aggregations?
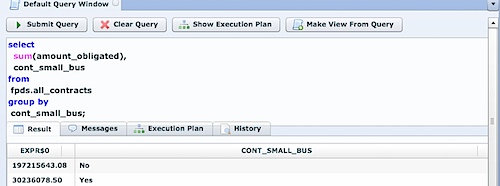
We’ll cover creating the “local” cached copy of the CouchDB dataset in the next section.