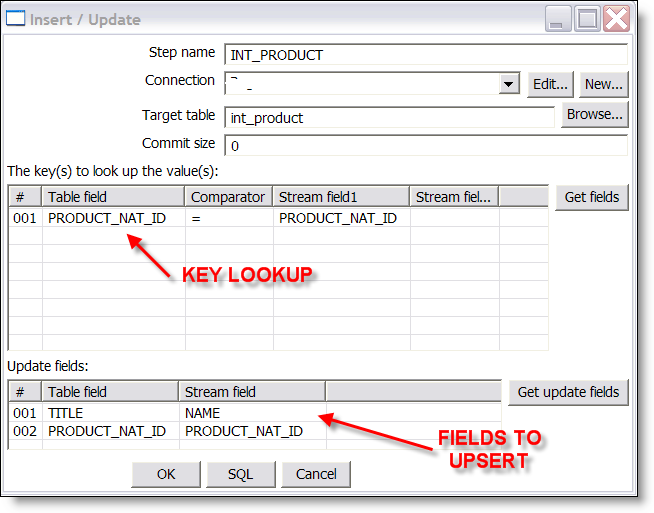
I just got on to Roland Boumans blog.
He has an excellent write up on how to get started with Pentaho Data Integration (aka Kettle):
Kettle is a free, open source (LGPL) ETL (Extraction, Transformation and Loading) tool. The product name should actually be spelled as K.E.T.T.L.E, which is a recursive acronym for "Kettle Extraction, Transport, Transformation and Loading Environment".
….
An interesting feature of Kettle is that it is model-driven. Both Spoon and Chef offer a graphical user interface to define the ETL processes on a high level. Typically, this involves no actual programming at all – rather, it’s a purely declarative task which results in a model.
He wonders at the end about how Kettle is deployed inside of Pentaho. That’s a great question and something Pentaho/Matt have been working at over the past few months. Perhaps I can shed a bit of light on this.
In the latest build of Pentaho (I used 1.1.6 for the below screenshots) we ship an example of a Kettle mapping returning a result set which demonstrates the great architectures of both Kettle and Pentaho. Kettle provides an easy way for creating plugins and interfaces for steps allowing Pentaho to access data at the "end" of a transformation. Pentaho has a multipurpose result set object which allows for reports to key off of "data" instead of a SQL Result or an MDX Result, or in this case, a real time data slurp (EII result?!?).
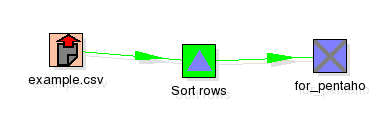
The transformation in spoon looks like this:
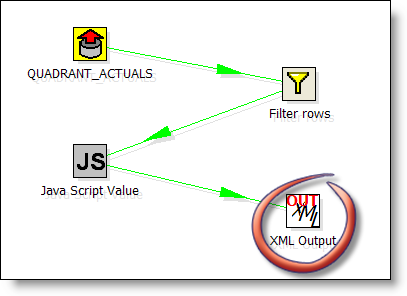
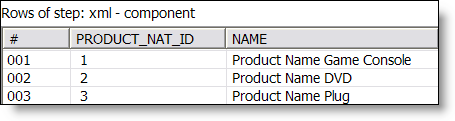
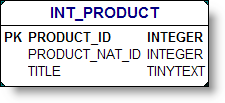
It reads data from the Pentaho sample database (QUADRANT_ACTUALS) filters, and does some calculcations and places then in an operator XML Output. This output operator is superflous, the KettleComponent (from Pentaho) sources the data DIRECTLY from the in memory XML Output object in Kettle.
The ETL example is basic; it doesn’t even place the data slurped from Kettle into a nicely formatted report.

Just to be clear on what you’re seeing…
Pentaho users gain the full power of the Pentaho Data Ingegration tool (proper ETL sorts, groups, XML, csv, xml, filters, calculations, database lookups, aggregations, etc) when used as a SOURCE for their reports. A full ETL tool where you don’t HAVE to persist the data to tables or files or anything.
If it suits your needs, you can simply run your ETL everytime your report is run and you never have to build a staging area, data warehouse, or OLAP cubes. Your mileage may vary and I don’t think this is wholesale replacement for a data warehouse at all! Just a great way to provide additional options for BI developers.
Going beyond a single transformation in Pentaho we are currently augmenting this component to allow you to execute Chef Jobs from inside Pentaho. I have no idea when that code is included in a release but I’ll be sure and blog about it here. That means that you can schedule your "DW load process" or "Data Integration Routines" to run from inside Pentaho. I’ll post an example of that shortly…
Again, check out Rolands article! It’s a great addition to the pentaho blogosphere.